Inside kube-scheduler: The Plugin Framework That Powers Kubernetes Scheduling
*This is the first in a series of blog posts exploring the Kubernetes kube-scheduler from the perspective of someone who has dug deep into the codebase and wants to share their findings professionally.*
Introduction
The Kubernetes scheduler (`kube-scheduler`) is one of the most sophisticated components in the Kubernetes control plane. Having spent considerable time analyzing its codebase, I’ve been fascinated by its elegant architecture and the intricate dance between its various components. This series aims to provide a comprehensive, technical deep dive into how this critical component works, written from the perspective of someone who has traced through the code and wants to share those insights.
The scheduler’s responsibility appears straightforward: assign newly created pods to suitable nodes. However, the implementation orchestrates a complex interaction between plugins, queues, caches, and API calls. Through this analysis, I realized that the scheduler’s true power lies in its plugin framework, where even fundamental operations such as resource checking and pod binding are implemented as plugins.
This marked the beginning of a deeper understanding that I’m excited to share through this series.
The Plugin-First Architecture: Framework as Core
My initial exploration of the scheduler code revealed a fundamental architectural insight that challenged my preconceptions. I expected to find core scheduling logic with plugins as optional extensions, but the reality proved quite different.
From inspecting the scheduler loop implementation, I discovered that the scheduler’s core strength lies in its plugin-first architecture, where even the most basic scheduling operations are implemented as plugins, while the scheduler core provides sophisticated orchestration logic.
The scheduler core doesn’t make scheduling decisions directly; instead, it orchestrates plugin execution and manages the overall process.
This fully pluggable architecture, introduced through the Scheduling Framework enhancement (GA since v1.19), enables features like asynchronous preemption (alpha since v1.32) and dynamic resource allocation (GA since v1.34).
The Plugin Framework: The Core of Everything
Code tracing shows that the Plugin Framework isn’t merely one component among many — it is the scheduler. Everything else exists to serve it. The framework provides:
Plugin Execution Environment
Extension Points: 12 well-defined hooks where plugins can inject logic (detailed in the next Blog Post)
Lifecycle Management: Orchestrates plugin execution in the correct order
Data Sharing: Provides `CycleState` for plugins to communicate
Profile Management: Different scheduling profiles can have completely different plugin sets
All plugins implement the `framework.Plugin` interface and are invoked via extension points defined in `framework/runtime/framework.go`. The `CycleState` is an in-memory, per-pod data store passed between plugins within a single scheduling cycle, distinct from the scheduler cache, which maintains cluster-wide state.
Plugin Registry & Profiles
The framework manages plugins through profiles, where each profile is essentially a different scheduler configuration:
type frameworkImpl struct {
registry Registry
snapshotSharedLister framework.SharedLister
waitingPods *waitingPodsMap
scorePluginWeight map[string]int
preEnqueuePlugins []framework.PreEnqueuePlugin
enqueueExtensions []framework.EnqueueExtensions
queueSortPlugins []framework.QueueSortPlugin
preFilterPlugins []framework.PreFilterPlugin
filterPlugins []framework.FilterPlugin
postFilterPlugins []framework.PostFilterPlugin
preScorePlugins []framework.PreScorePlugin
scorePlugins []framework.ScorePlugin
reservePlugins []framework.ReservePlugin
preBindPlugins []framework.PreBindPlugin
bindPlugins []framework.BindPlugin
postBindPlugins []framework.PostBindPlugin
permitPlugins []framework.PermitPlugin
// ... other fields
}Here is a flowchart diagram for the kube-scheduler framework initialization flow:
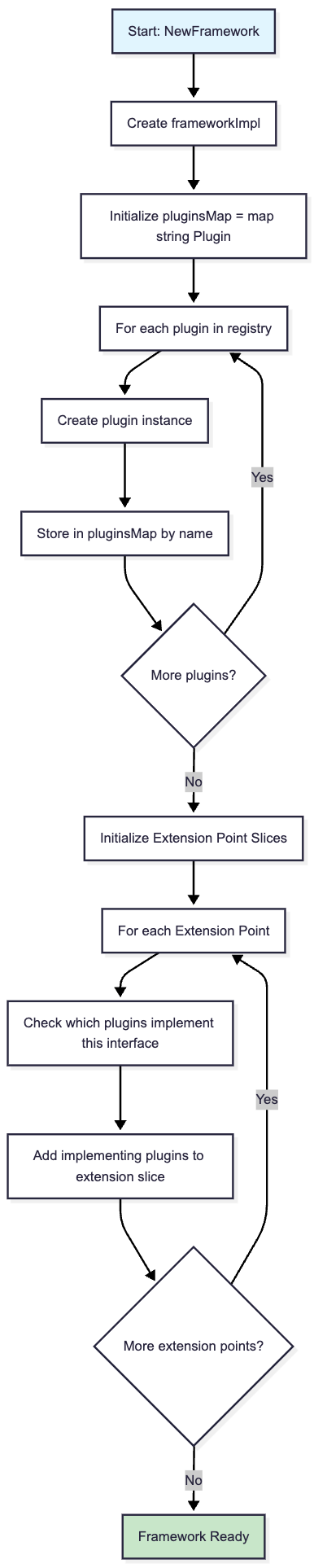
What I found particularly remarkable is that even basic operations like node filtering, resource checking, and pod binding are implemented as plugins. There’s no “core scheduling logic” that can’t be replaced.
Supporting Infrastructure: Everything Else
While the Plugin Framework orchestrates scheduling decisions, plugins cannot operate in isolation. They require consistent data, event synchronization, and external interfaces to function effectively. This is where the supporting infrastructure becomes crucial — it provides the foundation that enables the framework-centric design to work seamlessly.
All other components exist to enable the Plugin Framework to work effectively:
1. Orchestration Infrastructure
Scheduler Core: Coordinates the plugin framework execution.
Cycle Management: Manages synchronous and asynchronous scheduling cycles.
Error Handling: Provides cleanup and recovery mechanisms for plugin failures.
2. State Management Infrastructure
Scheduling Queue: Manages pod state transitions and provides pods to plugins for processing.
Cache: Maintains cluster state snapshots that plugins use for scheduling decisions.
Node Information: Provides consistent node data to plugins across scheduling cycles.
3. Event & Data Infrastructure
Informers: Feed real-time cluster events to plugins and supporting infrastructure.
Event Handlers: Process cluster changes and trigger appropriate plugin actions.
State Synchronization: Ensures consistency between plugin decisions and actual cluster state.
4. External Interface Infrastructure
API Dispatcher: Handles API operations triggered by plugins (e.g., binding and status updates).
Metrics System: Instruments plugin execution and system performance.
Configuration Management: Manages profiles and plugin configurations.
The Two Main Operational Cycles
The scheduler operates through two distinct but coordinated cycles (detailed execution flow covered in the upcoming blogs):
Synchronous Scheduling Cycle
The synchronous scheduling cycle is where plugins make their core scheduling decisions. It runs immediately when a pod is selected from the queue and must complete before moving to the next pod. This cycle includes the main scheduling phases and is synchronous because it must provide a deterministic, consistent result before proceeding.
Asynchronous Binding Cycle
The asynchronous binding cycle handles the actual binding of the pod to the selected node. It runs in a separate goroutine and can take time, potentially fail, or be interrupted. This cycle includes binding phases and API server updates, allowing the scheduler to continue processing other pods while binding operations are in progress. This pipeline parallelism is crucial for scheduler performance, as it enables the scheduler to continue scheduling other pods while previous pods are being bound.
Performance Considerations
The scheduler includes several key performance optimizations:
Snapshot-based State: The supporting infrastructure uses snapshots of cluster state rather than live queries, reducing API server load.
Percentage-based Node Scoring: The `percentageOfNodesToScore` parameter allows plugins to stop evaluating nodes once they’ve found enough feasible candidates. The implementation includes parallelism parameters that determine how node scoring runs concurrently. The concrete entry point for this logic can be found in `pkg/scheduler/scheduler_one.go` around `findNodesThatFitPod()`.
Plugin Metrics Sampling: Rather than measuring every plugin execution, the metrics system samples a percentage of scheduling cycles for performance data.
Goroutine Pool Management: The API Dispatcher utilizes goroutine pools to prevent resource exhaustion during high API call volumes.
The Complete Scheduling Flow
To better understand how the Plugin Framework orchestrates everything, let me walk you through the complete pod scheduling flow using a sequence diagram that illustrates the interactions between the Plugin Framework and its supporting infrastructure:
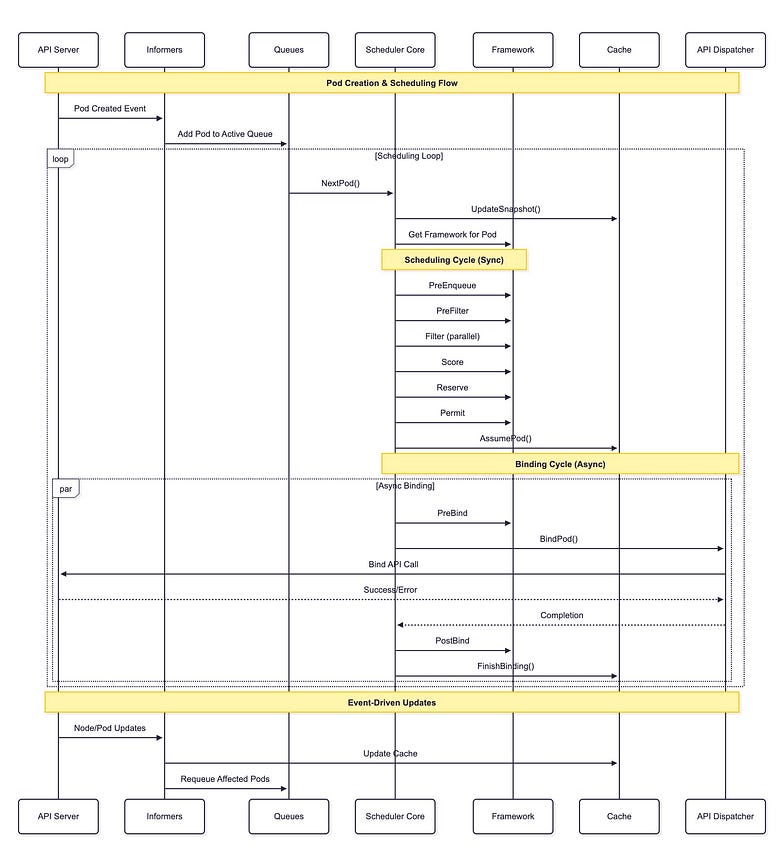
This sequence diagram illustrates the sophisticated orchestration between the Plugin Framework and its supporting infrastructure, showing how plugins make scheduling decisions while the supporting infrastructure handles state management, API interactions, and event processing. The implementation can be found in `pkg/scheduler/schedule_one.go`.
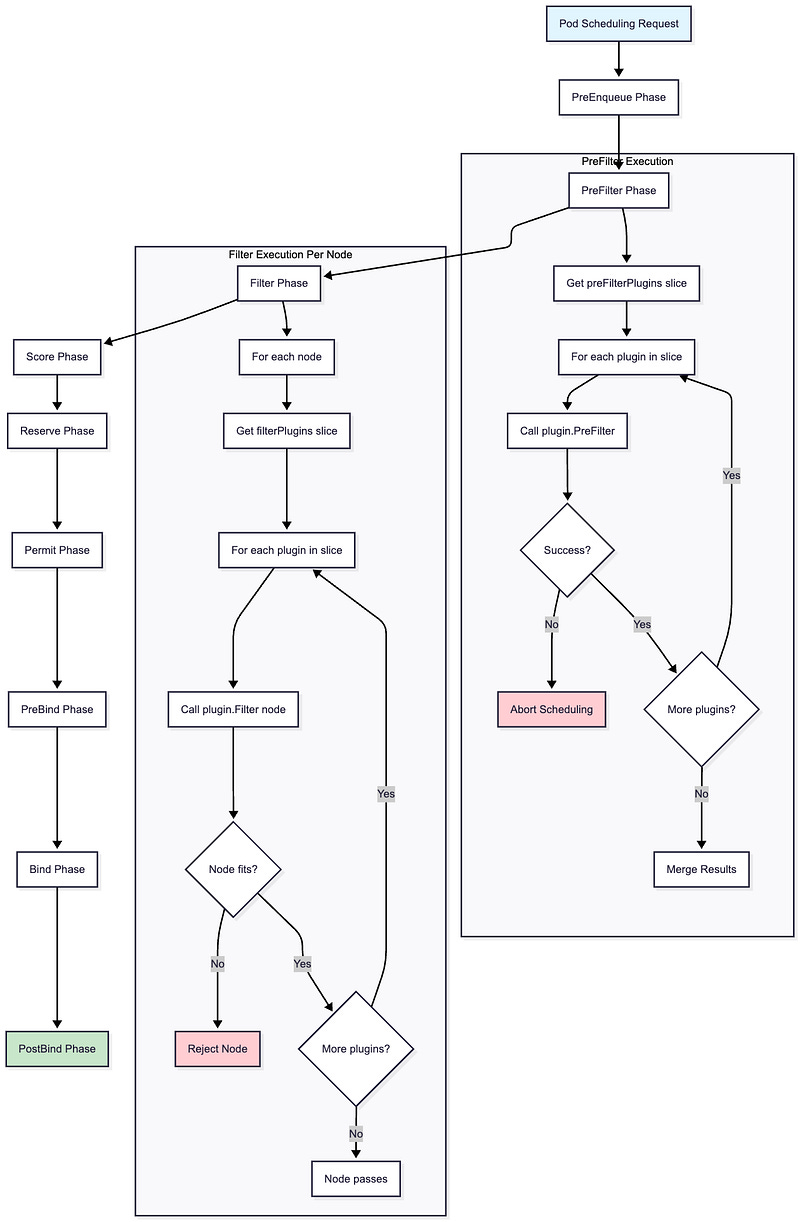
Conclusion
The Kubernetes scheduler’s architecture is fundamentally built around a Plugin Framework that serves as the core, with all other components existing as Supporting Infrastructure. This fully pluggable architecture enables complete pluginization of scheduling behavior while maintaining sophisticated orchestration logic in the scheduler core.
Understanding this architecture is crucial for anyone working with Kubernetes scheduling, whether you’re debugging scheduling issues, writing custom plugins, or simply trying to understand how your pods get scheduled. The framework’s extensibility, combined with the supporting infrastructure’s reliability, makes the scheduler both robust and maintainable.
In the next post, I’ll dive deeper into the Plugin Framework, exploring how it orchestrates plugin execution, manages extension points, and provides the sophisticated environment that enables plugins to work effectively.
References
This analysis is based on the Kubernetes v1.34.0 codebase. The scheduler continues to evolve, but the core architectural principles remain consistent across versions.